作者:张国斌
20年多前,全球桌面GPU领域堪称春秋战国玩家众多,但最后仅有三家公司生存下来,它们就是Nvidia,AMD和英特尔,不过现在桌面GPU将由三国大战变成四国杀,因为,一个老牌玩家回来了,它就是Imagination Technologies公司,它的GPU IP将助力本土IC企业进入桌面GPU市场!
1995年,有一家叫VideoLogic的公司凭借在图形和视频捕捉能力在混战中的桌面GPU领域闯出一片天空,赢得了NEC等公司的青睐,后来,VideoLogic改名Imagination Technologies,并淡出桌面GPU领域转型成一家成功的移动GPU IP授权公司,提供GPU IP给其他公司设计出优秀的GPU,并吸引了英特尔、苹果的投资,其Power VR GPU一直用于苹果的御用移动GPU,虽然苹果在2017年号称要自己研发GPU,但是,2020年苹果还是跟Imagination签定了多年合作协议,主要原因有两个,一个是因为GPU研发难度确实大,另一个原因是Imagination手中握有大量GPU专利,而且是基础性技术专利,苹果很难绕过去。

现在,Imagination TechnologiesI凭借其IMG B 系列GPU又杀回到桌面GPU领域了,此外,它还要进入数据中心领域,这一次,Imagination 将在桌面和数据中心GPU领域大干一场!
先看个效果!
天时地利人和
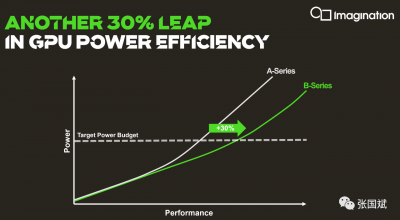
2020年10月13日,Imagination Technologies正式宣布推出全新的IMG B系列(IMG B-Series)图形处理器(GPU),B系列GPU可使Imagination的客户在降低功耗的同时获得比市场上任何其他GPU IP更高的性能水平。它提供了高达6 TFLOPS(每秒万亿次浮点运算)的计算能力,与前几代产品相比,功耗降低了多达30%,面积缩减了25%,且填充率比竞品IP内核高2.5倍!

“现在对Imagination来说是一个非常好的发展时机,我们继续保持在移动GPU领先的同时进入桌面和数据中心GPU市场,这两个市场目前急需新的玩家。”Imagination全球副总裁兼中国区总经理刘国军在接受电子创新网等媒体专访时指出,“桌面和数据中心领域由于长期被一些美资企业垄断,厂商‘苦秦久矣!所以,我们的GPU IP刚一推出就获得数家中国客户的青睐!有的已经在导入产品设计!未来不久你就会看到中国的桌面GPU。”
刘国军表示,去年Imagination IMG A系列GPU发布后,凭借出色的性能吸引了很多客户,有些客户希望获得性能更强大的GPU ,因此B系列应运而生,不过B系列GPU并不是A系列简单的升级而是通过提供各种不同的配置使客户有更广泛的选择。
Imagination公司CMO David Harold透露目前已经有五家客户在使用PowerVR GPU 架构开发面向台式机、高性能笔记本电脑和云领域的新产品。其中芯动科技Innosilicon在B系列GPU发布后,宣布将推出集成 IMG B 系列 BXT 多核GPU IP的GPUSoC,采用PCI-E 规格,面向桌面和数据中心应用。公司双方也会探索长期战略合作伙伴关系,将更强大的GPU SoC 推向市场。

凭借核心部分的可扩展性,IMG B系列GPU成为移动设备(从高端到入门级)、消费类设备、物联网、微控制器、数字电视(DTV)和汽车等多个市场的终极解决方案。此外,全新的多核架构使IMG BXT产品能够达到数据中心的性能水平,此外,B系列中还包括IMG BXS产品,这是首批符合ISO 26262标准的GPU内核,可以用于汽车领域。
据他介绍,IMG B系列GPU拥有四个产品系列,可以针对特定的市场需求提供专业的内核:

IMG BXE:实现绚丽的高清显示——凭借一系列专门针对用户界面(UI)渲染和入门级游戏设计的GPU内核,BXE系列每个时钟周期可以处理从1个像素到高达16个像素,从而可支持从720p到8K的分辨率。与上一代内核相比,BXE实现了多达25%的面积缩减,同时其填充率密度高达竞品的2.5倍。
IMG BXM:难以置信的图形处理体验——一系列性能高效的内核在紧凑的硅面积上实现了填充率和计算能力的最佳平衡,可以为中档移动端游戏以及用于数字电视和其他市场的复杂UI解决方案提供支持。
IMG BXT:前所未有的性能——可以为从手持设备到数据中心等现实世界的应用提供难以置信的高性能。该旗舰款B系列GPU是一个四核部件,可以提供6 TFLOPS的性能,每秒可处理192 Gigapixel(十亿像素),拥有24 TOPS(每秒万亿次计算)的人工智能(AI)算力,同时可提供行业最高的性能密度。
IMG BXS:面向未来的汽车GPU——BXS系列是符合ISO 26262标准的GPU,这使其成为迄今为止所开发的最先进的汽车GPU IP内核。BXS提供了一个完整的产品系列,从入门级到高级的产品,可为下一代人机界面(HMI)、UI显示、信息娱乐系统、数字驾舱、环绕视图提供解决方案,再到高计算能力的配置,则可支持自动驾驶和ADAS。
独特的多核架构将应用扩展到数据中心
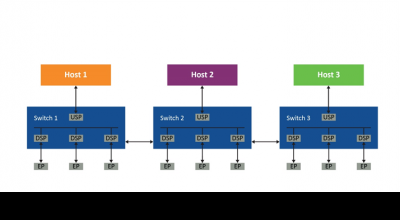
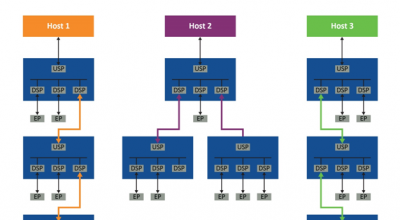
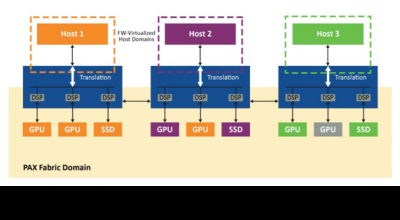
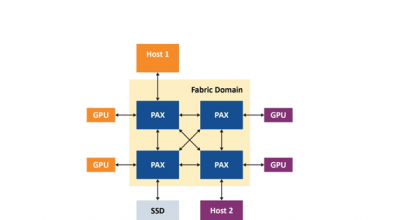
时昕博士指出目前GPU多采用多核设计,但是一般的多核GPU由于架构问题导致多核的效率并没有完全发挥,这次Imagination Technologies的B系列GPU采用了独特的多核架构,并整合了创新性的分散管理方法,从而可以提供高效的扩展特性,并且可与诸如小芯片(chiplet)架构等行业趋势相兼容。能够提供以前的GPU IP所不能提供的一系列性能水平和配置。


据悉,Imagination 的多核新方法是一种去中心化的设计思路---就是没有直接依赖于与中央单元的连接。其最简单的形式可视为多个 GPU,这些 GPU 存在于SoC 设计中,但具有多内核共同处理计算和图形的能力。因为Imagination 的GPU 是基于切片式延迟渲染,因此容易理解多个GPU如何通过让每个内核在不同的切片组上协同工作,以完成总渲染目标。
基于这样的多核架构,可以实现更多核心的高效GPU设计!这样特别适合计算中心进行大规模并行计算,所以,B系列GPU可以应用在数据中心领域。

据介绍,全新的多核架构已经针对BXT和BXM内核的每个产品系列进行了优化,利用多个主核的扩展特性实现了GPU内核的多核扩展。多核架构结合了所有内核的能力,可以为单个应用提供最大化的性能,或者根据需要支持不同内核去运行独立的应用。
另外,BXE内核提供了主核-次核的扩展模式,这是一种面积优化的解决方案,通过单个GPU内核提供了高性能,同时可以利用我们的HyperLane技术进行多任务处理。
此外,IMG B系列还使用了IMGIC技术,这是市场上最先进的图像压缩技术,可为客户提供节省带宽的新选择。IMGIC包含1种完全无损压缩模式和3种有损压缩模式,3种有损压缩模式的压缩率分别为75%(质量接近完美)、50%(视觉无损)、25%(最节省带宽)。IMGIC技术可以兼容B系列中的所有内核,这使得即便是最小的内核,也能够拥有Imagination行业领先的图像压缩技术优势。

汽车电子不能少
Imagination Technologies的Power VR GPU多年来一直是汽车数字显示御用GPU ,TI、瑞萨等汽车电子方案都采用的是PowerVR GPU,因此Imagination 也和tier1汽车供应商保持了紧密的合作关系,随着电动汽车,智能驾驶舱的兴起,汽车领域涌入了新的玩家,汽车GPU的开发也有了新的模式。对此,刘国军表示Imagination也看到了这样的趋势 ,这次新推出的IMG BXS就是面向未来的汽车GPU——而且BXS系列是符合ISO 26262标准的GPU,这使其成为迄今为止所开发的最先进的汽车GPU IP内核。

BXS汽车GPU内核也利用了多主核可扩展的特性,来支持性能扩展,以及跨多个内核进行安全检查,以确保正确运行。


目前人工智能技术正在赋能千行百业,与个各种应用深度融合,Imagination在这个领域起步较早,2017年,就率先发布了神经网络加速器产品PowerVR 2NX NNA,目前已经非要发布第四代产品,据介绍,Imagination目前有AI SYNERGY协同技术,让GPU不仅能处理图像,还可以处理可编程AI并和NNA协同起来,这样的人工智能处理更灵活。

最后剧透一下,移动领域的光线追踪技术就要来了,在这个领域,Imagination已经耕耘了近10年,在这次发布会上,Imagination技术产品管理高级总监Kristof Beets表示对于光线追踪技术,只有到了Level 4,才能实现最好的用户体验、更高算力、更低带宽,可实现桌面级高效性能的提升。而在明年的C系列GPU中,将支持这个leverl 4光线追踪技术!那将是引领移动GPU颠覆性的技术应用!

Imagination目前是100%中资控股,拥有广泛领先的IP产品,有这样一家强大的全球领先的IP公司是本土半导体之幸,目前,搭载Imagination IP的芯片产品累计出货量超过110亿颗,随着本土国产替代大潮兴趣 ,未来Imagination必将发挥更大作用!期待更多本土IC巨头崛起!
注:本文为原创文章,转载请注明作者及来源