
作者:电子创新网张国斌
2026年6月14日,小米新媒体高级工程师邹师傅发文热议“某大模型重新出山”,直言担忧行业陷入营销战与情怀捆绑,随后火速道歉澄清,引发全网关于大模型竞争底线的激烈探讨。

今天,该工程师再次道歉并发言澄清不针对任何友商。
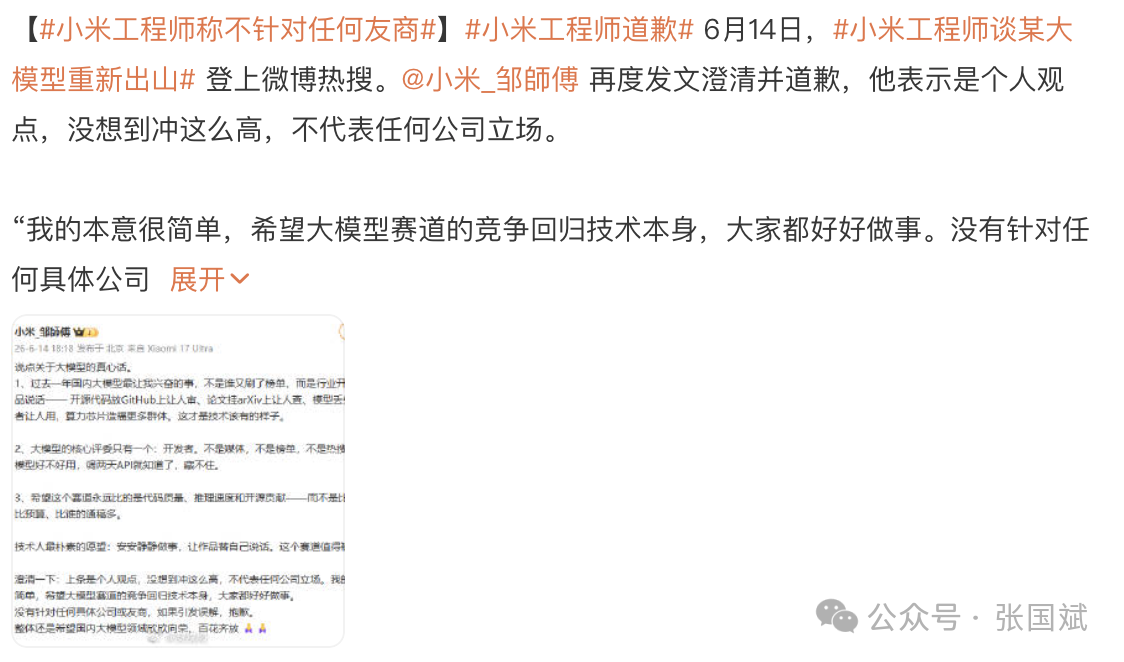
小米工程师发言核心内容包括:
欢迎良性切磋:该工程师明确表示欢迎新玩家入场进行纯粹的技术竞争,认为多一个认真做模型的厂商对行业和用户都有积极意义。
警惕非技术竞争:表达了对竞争风向的担忧,指出真正可怕的并非技术落后,而是赛道偏离硬实力比拼,滑向“比嗓门、拼情怀、搞捆绑”,特别反对将商业竞争与国产算力芯片及家国情怀强行关联。
呼吁珍惜务实氛围:强调过去一年国内大模型圈难得形成了“靠作品说话”的风气(如DeepSeek靠开源、MiMo靠论文、Qwen靠口碑),认为这种无是非争端的技术净土来之不易。
反对舆论污染:强烈反对新选手以饱和式舆论轰炸和有组织拉踩的方式入场,预判行业可能因此陷入内部厮杀与站队,迫使技术人员分散精力应对公关战。
笔者认为这些观点都是比较中肯的,这两天舆论一直认为此言论指向华为盘古大模型,因为在12日的华为开发者大会(HDC 2026)上余承东宣布盘古大模型全面升级并亲自挂帅,因此多数网友认为其矛头暗指华为盘古大模型。
科普:12条指标鉴定大模型优劣
今天,我们抛开口水战,就谈谈如何鉴定大模型的优劣,这里分享12条指标。
首先我们要明确,大模型之间的竞争,早就不是简单比参数规模(Parameter Count),曾几何时,大模型的竞争只有一个指标--参数规模(Parameter Count),从百亿到千亿,再到万亿——整个行业像极了当年的CPU频率大战:谁更大,谁更强,谁更贵,谁更先进,但问题是——用户根本不在乎你有多少参数。用户只关心三件事:你能不能答对、你会不会胡说、你贵不贵,于是,一个残酷的现实出现了:“参数崇拜”,正在变成AI行业最大的认知泡沫。
现在,大模型拼比的是系统工程能力的综合比拼。如果用行业视角来看,可以拆成三层:模型能力层、工程实现层、生态与商业层。
划重点,我们用三层12个指标来评比大模型的优劣。
一、核心:模型能力层(决定“聪不聪明”)
这是最直观、也是用户最容易感知的能力。
1)推理能力(Reasoning)
是否具备多步推理能力(Chain-of-Thought)
能否解决复杂逻辑问题(数学、代码、规划)
是否稳定(不会“忽然降智”)
→ 典型测试:
GSM8K(数学推理)
MATH
HumanEval(代码能力)
2)知识与理解能力(Knowledge & Understanding)
知识覆盖广度(通识 vs 专业)
上下文理解深度(长文本理解)
多语言能力
→ 关键指标:
MMLU(综合知识)
CMMLU(中文能力)
长上下文(128K / 1M tokens)
3)生成能力(Generation Quality)
文本是否自然、结构清晰
是否有“观点力”和逻辑组织能力
是否可控(风格、长度、格式)
→ 实际场景:
写报告
写代码
写营销内容(你现在就在用这个能力)
4)多模态能力(Multimodal)
图像理解(Vision)
视频理解(Video)
语音(ASR/TTS)
→ 判断标准:
是否“看懂图”还是只做caption
是否能做跨模态推理(图+文)
5)工具使用能力(Agent能力)
是否能调用外部工具(搜索、代码执行、API)
是否能分解任务(Task Planning)
是否具备“闭环执行能力”
→ 这已经是从“模型”走向“智能体(Agent)”的关键分水岭
二、工程实现层(决定“好不好用”)
很多人忽略这一层,但产业竞争真正拉开差距的就在这里。
6)推理效率(Inference Efficiency)
延迟(Latency)
吞吐(Throughput)
每token成本($/token)
→ 关键技术:
KV Cache优化
Speculative Decoding
模型量化(INT4 / INT8)
7)稳定性与幻觉控制(Hallucination)
是否胡编乱造
是否能“承认不知道”
是否有事实一致性(Factuality)
→ 企业级应用最看重这一点
8)对齐能力(Alignment)
是否符合人类价值和指令
是否“听话”(Instruction Following)
是否安全(不会输出违规内容)
→ 技术手段:
RLHF(人类反馈强化学习)
Constitutional AI
9)可扩展性(Scalability)
是否支持超长上下文
是否支持并发
是否适合部署(云 / 边缘)
三、生态与商业层(决定“能不能赢”)--这一层才是决定谁能成为“平台”的关键。
10)开发者生态(Ecosystem)
API是否易用
是否有插件 / 工具链
是否支持微调(Fine-tuning)
→ 类比:
不只是“模型”,而是“AI操作系统”
11)数据飞轮(Data Flywheel)
是否有持续数据反馈
是否能快速迭代模型
→ 本质:谁的数据更“新鲜 + 高质量”
12)成本与商业化能力
推理成本是否足够低
是否能规模化部署
是否有清晰商业模式
大家记住了吗?12个指标!
四、更直观的评比:一个“行业级评估模型”
这里推荐一个“五维评分模型”:
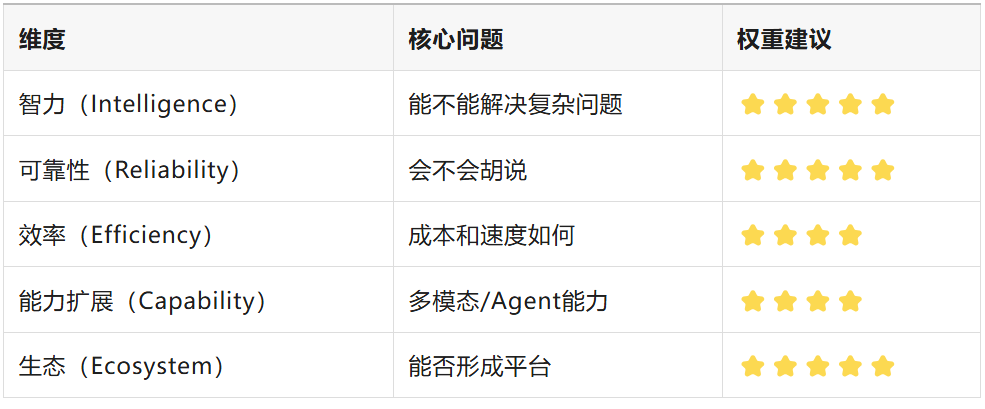
一句话总结“决定胜负的,不是模型本身,而是模型+工程+生态的三位一体”
事件回溯:

“在我余承东的字典里,没有第二,只有第一。”6月12日下午在华为开发者大会(HDC 2026)上,华为常务董事、产品投资评审委员会(IRB)主任、终端BG董事长余承东说道。他在现场除了发布HarmonyOS 7操作系统外,还宣布华为将推出开源盘古openPangu 2.0大模型,包括openPangu 2.0 Pro,总参数量5050亿,激活参数量180亿;以及openPangu 2.0 Flash,总参数量920亿,激活参数量60亿。
他透露,openPangu计划6月30日把七大组件陆续开源上线,业界开源的主要是模型结构、模型权重、技术报告和推理代码等四项,而华为还多开源了三项,包括预训练代码、后训练代码、训推算子,“让大家使用昇腾、使用盘古大模型更高效、更易用”。
目前国内大模型进入到残酷的竞争时代,竞争是一件好事,希望通过竞争,优秀的大模型脱颖而出!为产业赋能!
注:本文为原创文章,未经作者授权严禁转载或部分摘录切割使用,否则我们将保留侵权追诉的权利